
Lake Formation とは
Lake Formation は、データレイクを構築、運用するための AWS マネージドサービスです。
データレイクについては、AWS のドキュメントで以下のように説明されています。
データレイクとは
https://aws.amazon.com/jp/what-is/data-lake
データレイクは、規模にかかわらず、すべての構造化データと非構造化データを保存できる一元化されたリポジトリです。データをそのままの形で保存できるため、データを構造化しておく必要がありません。また、ダッシュボードや可視化、ビッグデータ処理、リアルタイム分析、機械学習など、さまざまなタイプの分析を実行し、的確な意思決定に役立てることができます。
要するに、構造化・非構造化問わず、様々な形式のデータをそのままの形で保存できるリポジトリがデータレイクのようです。様々なデータを 1 つの場所に集中して保管することで、より多くのデータを分析に活用できるようになります。一方で、無造作に様々なデータを追加していると、データが多すぎるがゆえに必要なデータを見つけられなくなるという課題も生じます。
Lake Formation は、こういった課題を解決しつつ、簡単にデータレイクを構築、運用するためのサービスです。
以下の図にあるように Lake Formation は AWS Glue の拡張機能的な立ち位置のサービスとなっており、一部の機能では Glue のリソースを作成します。
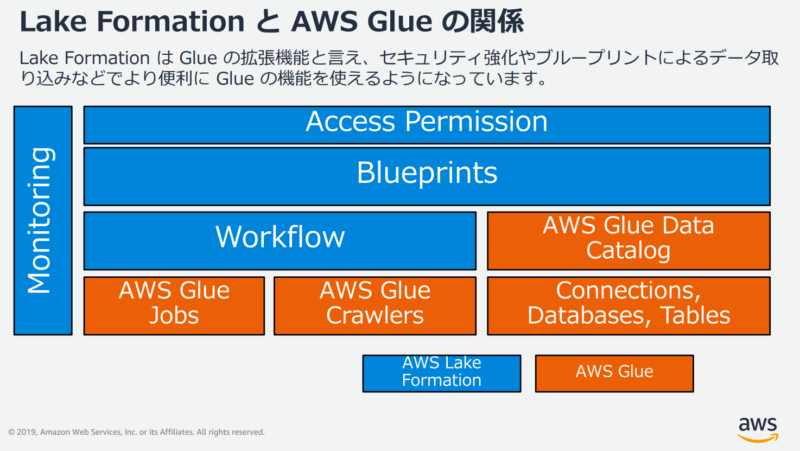
大まかな理解
Lake Formation の各機能について、ざっくりと説明します。
まず、先述の通り Lake Formation はデータレイクを構築、運用するための AWS マネージドサービスです。そして、データレイクはデータの形式を問わずにデータを保存するリポジトリのことでした。データレイクの運用は、データレイクに保存した様々な形式のデータを分析し、意思決定にデータを活用することを目的としています。
上記よりデータレイクの利用にあたって、以下のリソースが必要になります。
- データレイク本体
- データレイクに保存するためのデータ
- データレイクに保存されたデータを分析するためのサービス
データレイクには、構造化・非構造化問わず、様々な形式のデータが保存されます。データをただただ雑多に保存するだけでは、データレイクに保存されたデータがどのような形式のもので、何用のデータなのかわからなくなってしまいます。
データレイクを利用する目的はデータを分析することですので、保存されたデータを分析できるように整理する必要があります。そこで、データレイクに保存されたデータとセットで、そのデータの説明書も作っておく必要があります。
絵にすると、以下のような関係性です。
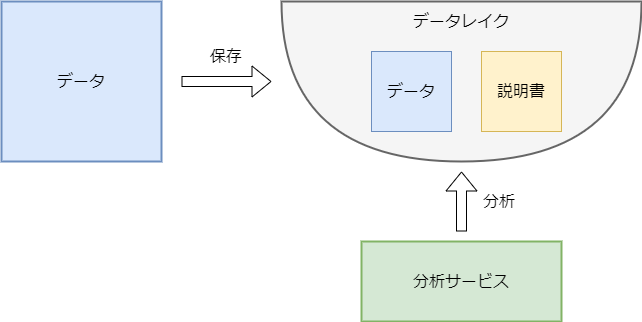
実際には、分析サービスを利用するユーザーによって、参照できるデータや説明書は異なるはずです。ユーザー A は、データ A を参照できるものの、ユーザー B はデータ A を参照できないなどの制御をする必要があります。
このデータや説明書に対するきめ細かなアクセス制御を管理するためのサービスが Lake Formation です。また、Lake Formation にはアクセス制御に加えて、データレイクにデータをインポートするブループリントと呼ばれる機能もあります。
これらを踏まえて、上の図を AWS サービスに置き換えて考えると以下のようになります。Lake Formation の主な機能は赤色の部分です。
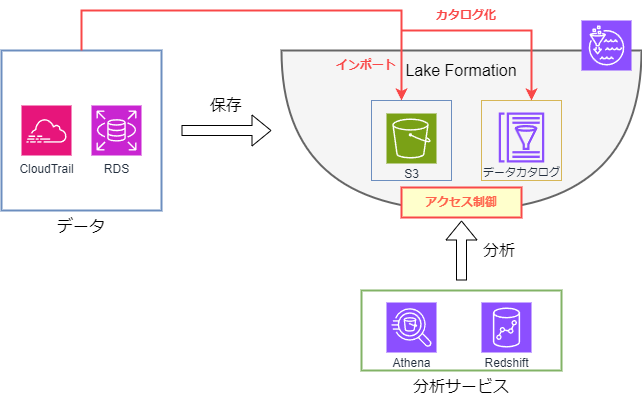
こうしてみると非常にシンプルですね。
機能
Lake Formation の主な機能であるブループリントとアクセス制御についてみていきます。
ブループリント
ブループリントは Lake Formation に標準で用意された、データを Lake Formation に取り込むための機能です。その名の通りブループリント自体は設計図で、ブループリント上で入力したパラメータをもとにワークフローを作成してデータを取り込みます。ワークフローは、Glue クローラー、ジョブ、トリガーをカプセル化したものです。
A workflow encapsulates a complex multi-job extract, transform, and load (ETL) activity. Workflows generate AWS Glue crawlers, jobs, and triggers to orchestrate the loading and update of data. Lake Formation executes and tracks a workflow as a single entity. You can configure a workflow to run on demand or on a schedule.
https://docs.aws.amazon.com/lake-formation/latest/dg/workflows-about.html
実際、Lake Formation で作成されたワークフローは Glue コンソールからも確認することができます。ワークフロー自体は Glue からも作成可能ですが、Lake Formation ブループリントで用意されているデータソースについては、Lake Formation ブループリントを利用したほうが楽にワークフローを構築できます。
Lake Formation では以下のタイプのブループリントを提供しています。
- データベース用ブループリント
- MySQL、PostgreSQL、SQL Server 、MariaDB、Oracle からデータをインポート可能
- データベースには JDBC で接続し、RDS や EC2 だけでなく、オンプレミスのデータベースも対象
- 一括データロードと増分データロードのいずれかを選択可能
- ログファイル用ブループリント
- AWS の主要なログ (CloudTrail、ALB、CLB) をインポート
- 一括データロードのみ
ワークフローの実行ユーザーは、ワークフローによって作成されるデータカタログテーブルに対して SELECT 権限を持ちます。
Lake Formation にデータを取り込むにあたって、必ずしもブループリントを使う必要はありません。別の方法で S3 にデータを保存し、その S3 を Lake Formation の管理下に置くことも可能です。
アクセス制御
Lake Formation の肝となる機能です。むしろ、ほぼほぼこの機能を利用するために Lake Formation を利用するかと思います。
Lake Formation のアクセス制御では、次の 2 つのレベルで権限を実装できます。
- データベースやテーブルなどのデータカタログリソースに対するメタデータレベル
- 統合された分析エンジンに代わって、S3 に保存されているデータへのアクセスを管理するストレージレベル
ここでは、それぞれの概要を説明します。アクセス制御の詳細は、以下の記事で取り上げています。

メタデータレベルのアクセス制御
データカタログに対するアクセス制御の設定です。メタデータレベルのアクセス権を付与することにより、プリンシパルはデータカタログ内のデータベーステーブルを作成、読み取り、更新、および削除できるようになります。
プリンシパルとデータカタログを紐づける方法として、名前付きリソース方式と LF タグベースの方式があります。
ストレージレベルのアクセス制御
データカタログテーブルに紐づく S3 に対してアクセスするプリンシパルを制御する設定です。
この設定を行う場合、Lake Formation に S3 の場所とともに、その S3 にアクセス可能な IAM role を設定します。ストレージレベルのアクセス制御が有効な S3 に紐づくデータカタログを使用する場合、Lake Formation はこの IAM role の一時的な認証情報を分析サービスに返却し、分析サービスは返却された一時的な認証情報を使用して S3 にアクセスしデータを取得します。
権限管理のワークフロー
次の図は、Lake Formation でのアクセス許可管理がどのように機能するか示しています。
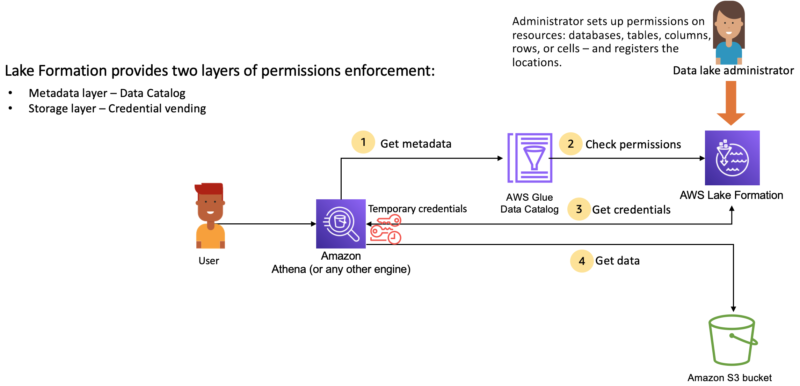
- メタデータの取得
- ユーザーは、Athena などの分析エンジンに対してクエリを実行します。
- Lake Formation と統合された分析エンジンは、リクエストされているテーブルを識別し、メタデータのリクエストをデータカタログに送信します。
- 権限の確認
- データカタログは、Lake Formation におけるユーザーの権限を確認します。
- ユーザーがテーブルへのアクセスを許可されている場合は、ユーザーが表示可能なメタデータをエンジンに返却します。
- 資格情報の取得
- データカタログは、分析対象データを保管する S3 が Lake Formation の管理配下にあるかを分析エンジンに連携します。
- S3 が Lake Formation に登録されている場合、分析エンジンはデータへアクセスするための一時的な認証情報を Lake Formation に要求します。
- S3 が Lake Formation に登録されていない場合、分析エンジンからのデータアクセスは S3 に対して直接行われます。
- データの取得
- ユーザーがテーブルへのアクセスを許可されている場合、Lake Formation は分析エンジンに一時的な認証情報を提供します。
- 分析エンジンは提供された一時的な認証情報を使用して、S3 からデータを取得します。
- 分析エンジンはジョブの実行を終了すると結果をユーザーに返却します。
チュートリアル
AWS の公式ドキュメントに Lake Formation のチュートリアルが用意されています。今回は、CloudTrail のログを Lake Formation に取り込むチュートリアルを通して、Lake Formation を利用する際の流れを確認しようと思います。

Lake Formation に関しては、以下のドキュメントで Lake Formation を利用するペルソナと推奨される IAM アクセス許可が紹介されています。今回のチュートリアルでも、このペルソナをベースに権限設定を行っています。

事前準備
AdministratorAccess をもつ IAM 管理者ユーザーで事前準備をしていきます。
データレイク管理者の作成
Lake Formation を初めて利用する場合、データレイク管理者を設定する必要があります。データレイク管理者は、データの場所とデータカタログリソースに対する Lake Formation アクセス制御を付与できる唯一の IAM User または IAM role です。
AdministratorAccess を持つ IAM 管理者は、データレイク管理者に設定しないことを推奨されているため、新しくデータレイク管理者用の IAM User を作成します。IAM コンソールから、datalake_admin という名前のユーザーを作成します。
今回のチュートリアル用にこちらを参考にして以下のポリシーを付与しました。
- AWSLakeFormationDataAdmin (データレイク管理者で必須)
- AWSGlueConsoleFullAccess (ワークフロー作成時に一部の glue アクションが必要)
- LakeFormationSLR
- UserPassRole
作成されたデータレイク管理者には、以下の暗黙的な Lake Formation 権限が付与されます。
https://docs.aws.amazon.com/lake-formation/latest/dg/implicit-permissions.html
IAM User の作成後、IAM 管理者ユーザーで Lake Formation コンソールにアクセスします。Lake Formation でデータレイク管理者を設定していない場合は “Welcome to Lake Formation” ウィンドウが表示されるので、先ほど作成した datalake_admin をデータレイク管理者に設定します。
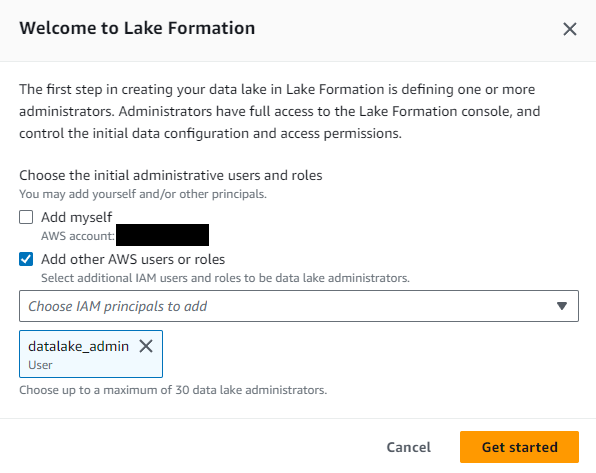
データレイクユーザーの作成
データレイクを利用するユーザーを作成します。
IAM コンソールから、datalake_user という名前のユーザーを作成します。
今回のチュートリアル用にこちらを参考にして以下のポリシーを付与しました。
- AmazonAthenaFullAccess
- DatalakeUserBasic
ワークフロー用 IAM role の作成
ブループリントから作成するワークフローが Lake Formation にデータを取り込む際に使用する IAM role を作成します。IAM コンソールから LakeFormationWorkflowRole という名前のロールを作成します。
今回のチュートリアル用にこちらを参考にして以下のポリシーを付与しました。
- AWSGlueServiceRole
- LakeFormationWorkflow
デフォルト権限モデルの変更
既存のデータカタログとの互換性を確保するため、Lake Formation はデフォルトで IAM アクセスコントロールのみを使用する設定となっています。この場合、ユーザーは IAM ポリシーと S3 バケットポリシーを通じて、データへのアクセスを制御されます。Lake Formation のアクセス制御を有効にするため、今回はこのデフォルト設定を無効にします。
[Data Catalog setting] メニューより “Default permissions for newly created databases and tables” 内のチェックを両方とも外します。
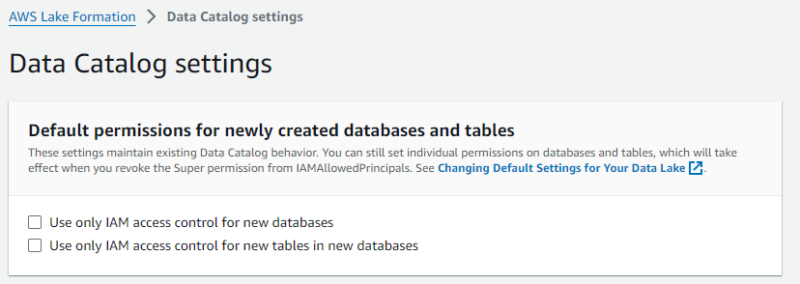
CloudTrail 証跡の作成
以下を参考に CloudTrail で証跡を作成し、S3 に CloudTrail イベントを出力しておきます。
https://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-create-a-trail-using-the-console-first-time.html
ワークフロー用 IAM role の権限追加
LakeFormationWorkflowRole に対して、CloudTrail からログを読み取るための権限を追加します。
今回のチュートリアル用にこちらを参考にして以下のポリシーを付与しました。
- DatalakeGetCloudTrail
Lake Formation に S3 を登録する
Lake Formation でデータを保管するための S3 を作成します。今回は k-log-lf-bucket という名前の S3 バケットを作成しました。
作成した S3 バケットを Lake Formation に登録していきます。datalake_admin でサインインして Lake Formation コンソールを開き、[Data lake locations] メニューにて “Register location” をクリックします。
- 作成した S3 バケットを S3 パスに指定します。
- IAM role はデフォルトで選択されているサービスロールのままとします。
- 権限モードでは Lake Formation を選択します。
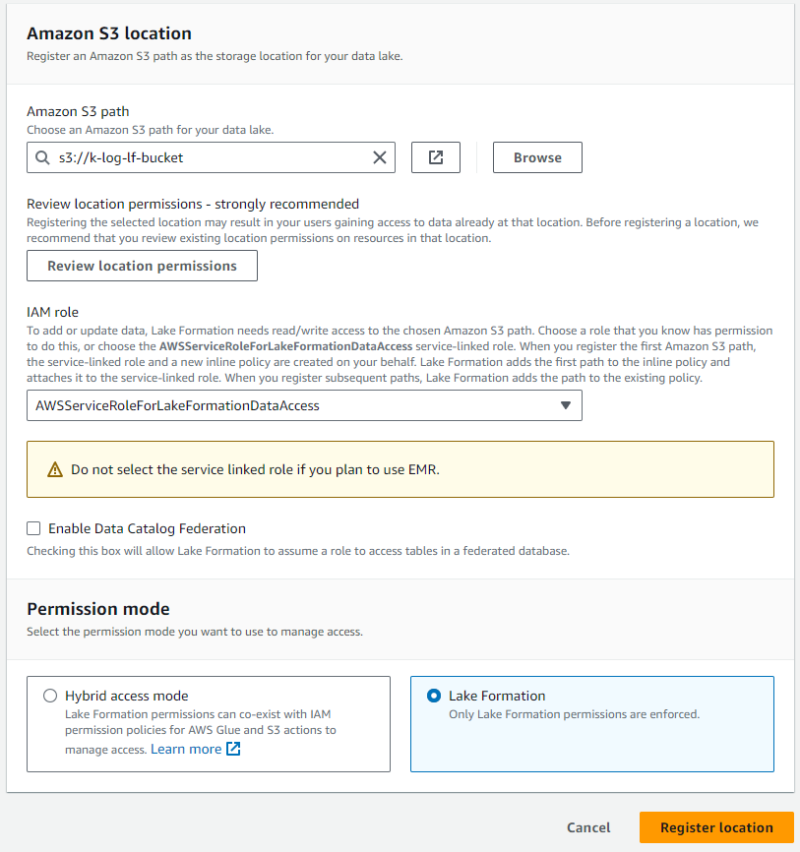
これで対象の S3 バケットを Lake Formation の管理下とすることができました。
データロケーションへの許可
Lake Formation に S3 を登録できたので、次は登録した S3 を参照するデータカタログの作成操作を制御します。データレイク管理者以外のユーザーが Lake Formation に登録された S3 パスに対して、好き勝手にデータベースやテーブルを作成できないように制限するための設定です。後の手順で作成するワークフローがデータを取り込めるように、ワークフローで使う IAM role に対してデータロケーションへの許可を付与します。
[Data locations] メニューにて “Grant” をクリックします。
- 事前準備で作成した
LakeFormationWorkflowRoleをプリンシパルに指定します。 - 「Storage locations」には Lake Formation に登録した S3 バケットを指定します。
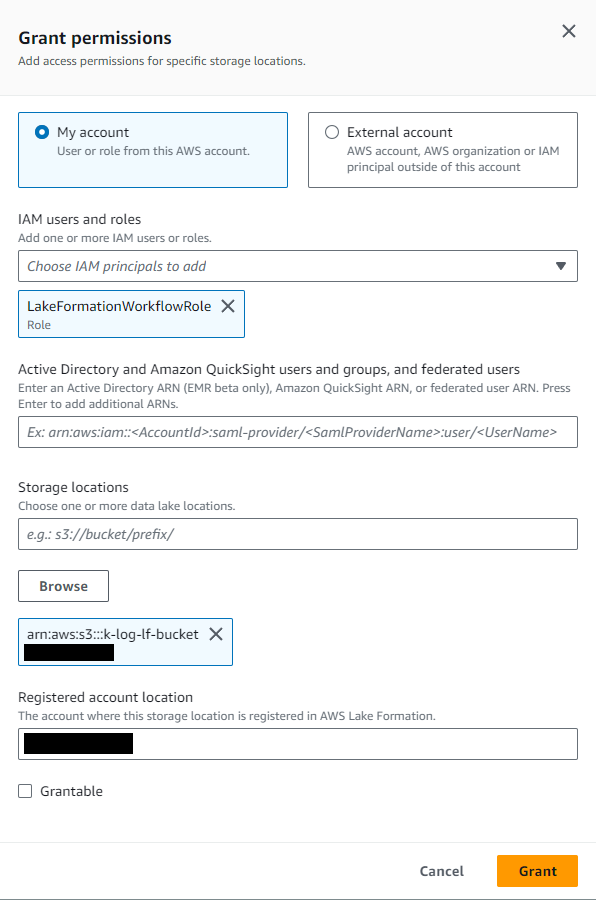
前項の [Data lake locations] と名前が似ていて紛らわしいのですが、[Data locations] は [Permissions] セクション内、[Data lake locations] は [Administration] セクション内のメニューであり、役割が異なりますので注意しましょう。
データベースの作成
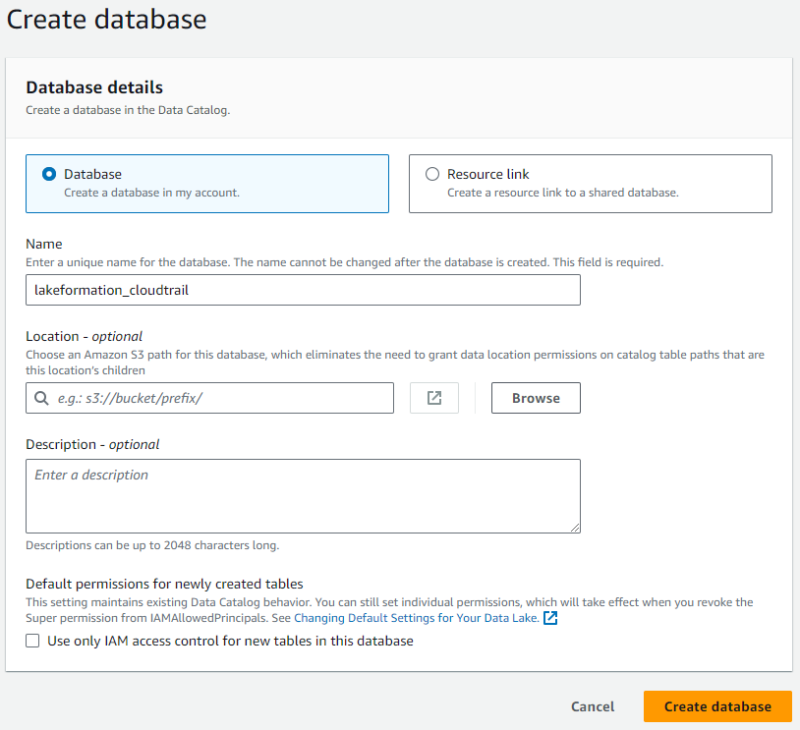
[Databases] メニューを開き “Create database” をクリックして、データカタログにデータベースを作成します。
テーブル作成権限の付与
ワークフローで使う IAM role に対して、データカタログにテーブルを作成するための権限を付与します。
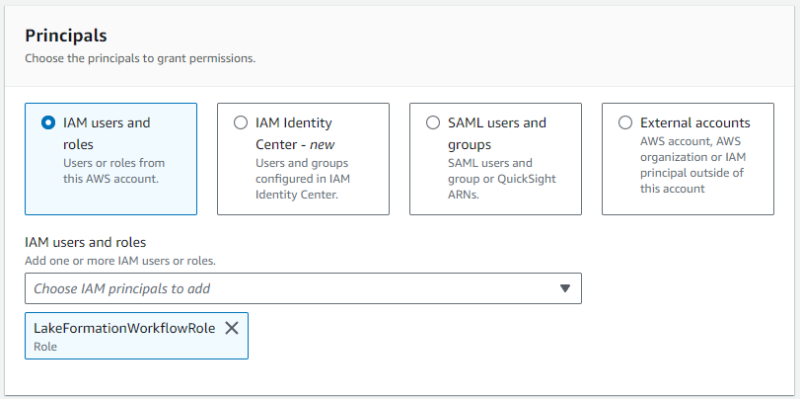
[Databases] メニューで先ほど作成した lakeformation_cloudtrail を選択し、”Actions” > “Grant” とクリックします。
- プリンシパルに
LakeFormationWorkflowRoleを指定します。 - 作成したデータベースが対象リソースに選択されていることを確認します。
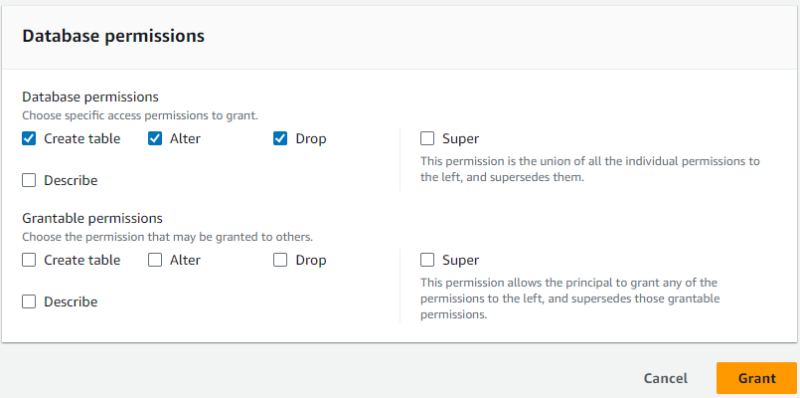
- 「Database permissions」として
Create table、Alter、Dropを選択します。
ブループリントを使用してワークフローを作成する
ブループリントを使用して CloudTrail のログをインポートするワークフローを作成します。
[Blueprints] メニューで “Use blueprint” をクリックしてブループリントを使用します。
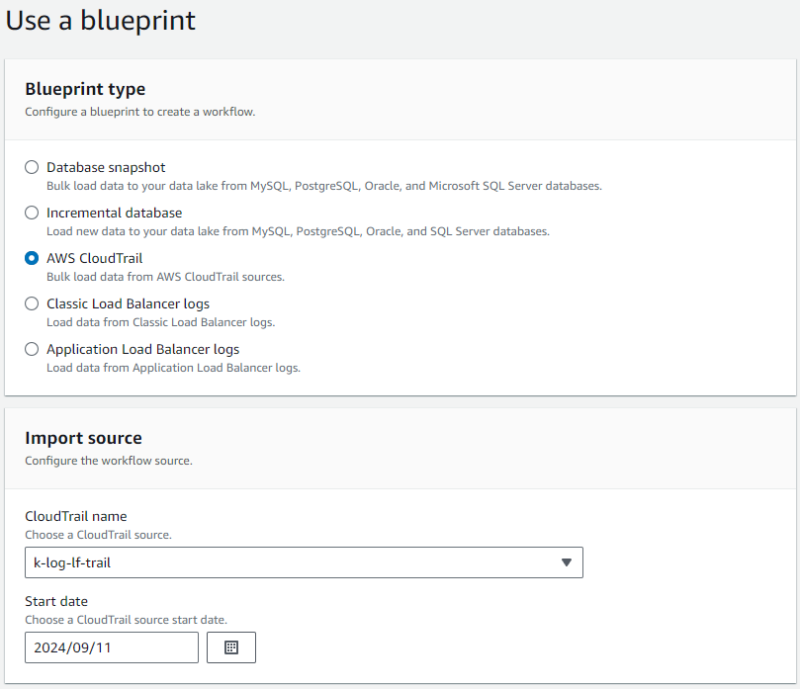
- 「Blueprint type」は CloudTrail を選択します。
- インポートする証跡名とインポートするログの最初の日を指定します。
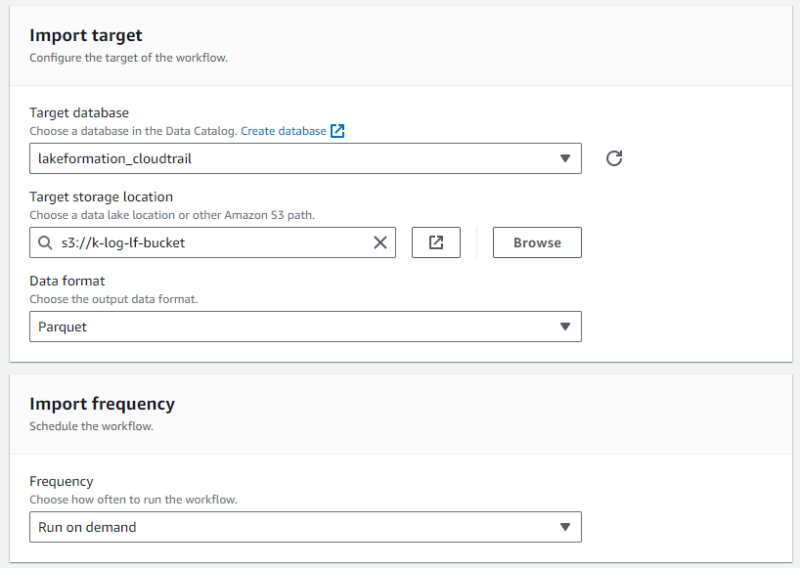
- ターゲットには、先に作成したデータカタログデータベースと Lake Formation に登録した S3 を選択します。
- 実行頻度をオンデマンドで設定します。
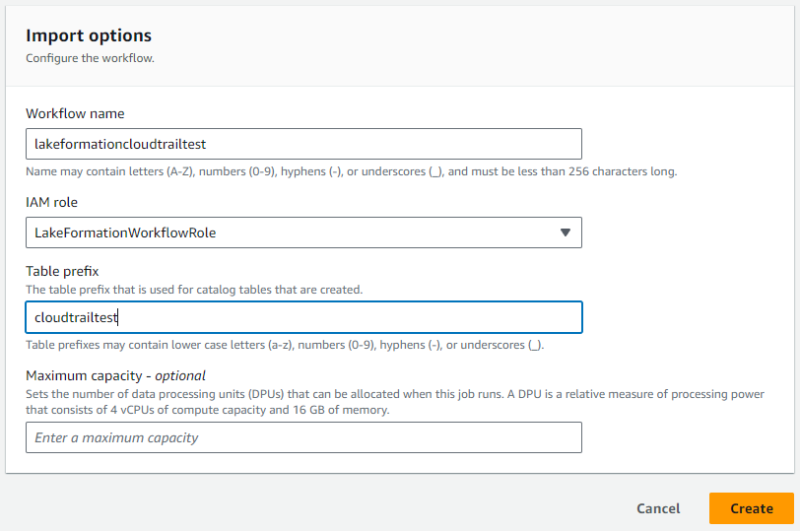
- ワークフロー用に作成しておいた IAM role を指定し、ワークフロー名やテーブルのプレフィックスを指定します。
ワークフローの実行
ブループリントからワークフローが作成されたら、作成されたワークフローを実行してログを Lake Formation に取り込みます。今回は、実行頻度をオンデマンドで設定しているため、手動でワークフローを実行します。
[Blueprints] メニューで作成したワークフローを選択し、”Actions” > “Start” とクリックしてワークフローを実行します。ワークフローの完了まで、しばらく待ちます。
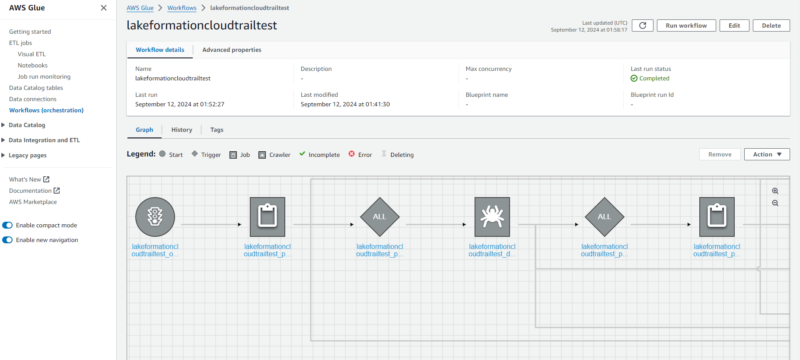
ワークフローが完了すると指定した S3 に CloudTrail ログがインポートされ、データカタログにはテーブルが作成されます。

また、Glue コンソールからブループリントで作成されたワークフローやワークフローに含まれる Glue リソースを確認することも可能です。
ユーザーへの権限付与
インポートしたデータをクエリできるように datalake_user に対して SELECT 権限を付与します。
[Databases] メニューにて lakeformation_cloudtrail を選択し、”Actions” > “Grant” とクリックします。
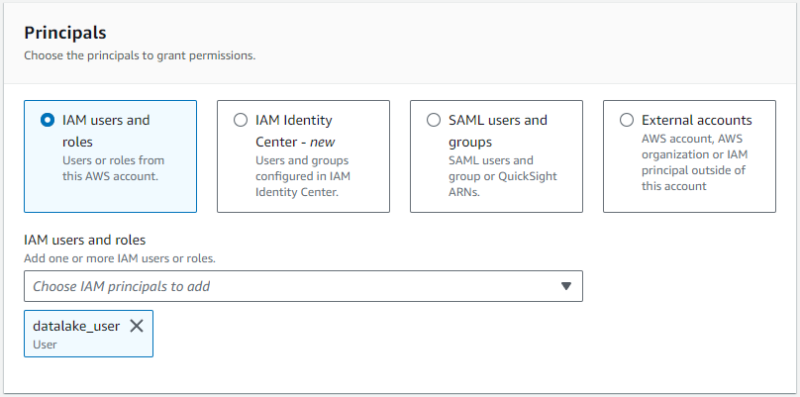
- プリンシパルに
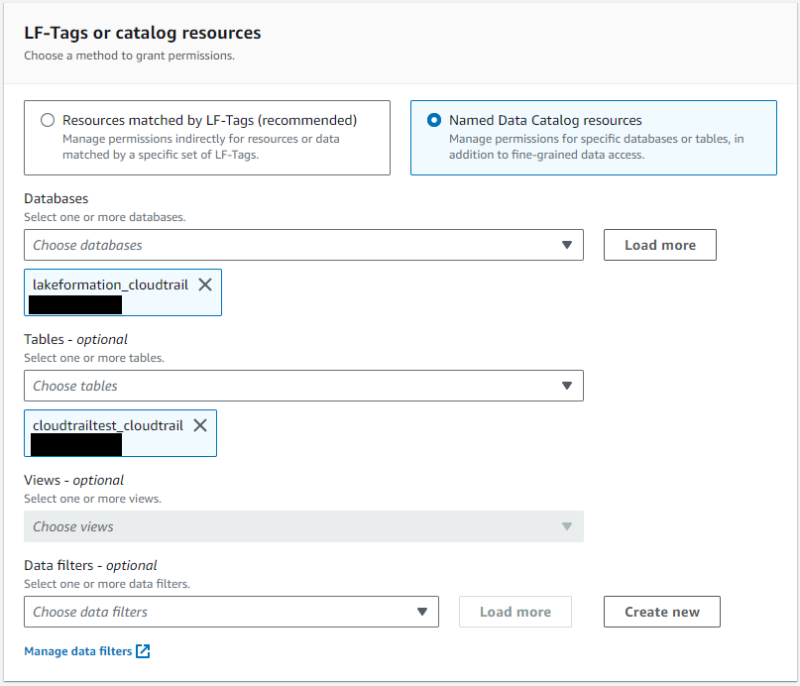
datalake_userを指定します。 - 対象リソースにワークフローで作成されたテーブルを指定します。
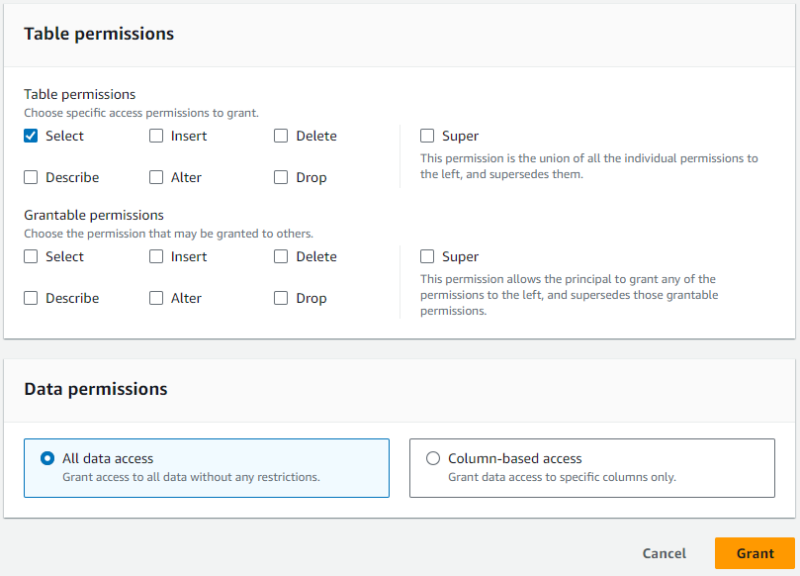
- テーブル権限として
Selectにチェックをいれます。
ユーザーでクエリする
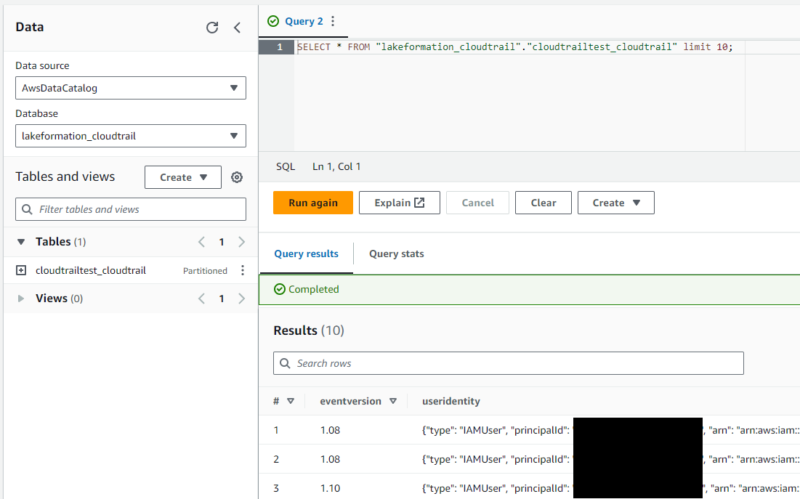
datalake_user でサインインし、Athena コンソールを開きます。
クエリを実行して SELECT 文が実行できることを確認します。
一方で、今回 SELECT 以外の操作は許可していないため、例えば CREATE TABLE などは失敗します。
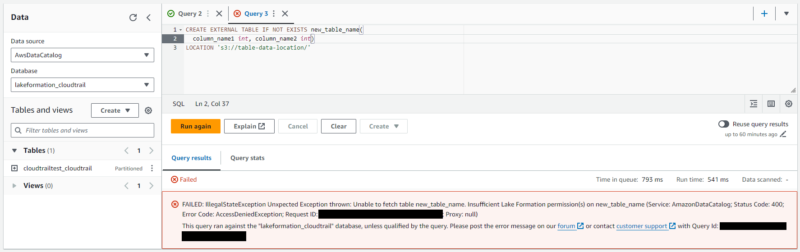
エラーメッセージを確認してみると Lake Formation で権限が許可されておらず、操作に失敗したことがわかります。
FAILED: IllegalStateException Unxpected Exception thrown: Unable to fetch table new_table_name. Insufficient Lake Formation permission(s) on new_table_name (Service: AmazonDataCatalog; Status Code: 400; Error Code: AccessDeniedException; Request ID: xxxxx; Proxy: null)まとめ
この記事では、Lake Formation の概要を説明し、チュートリアルに沿って具体的な操作や動作について確認してきました。
なかなか初見ではとっつきづらいサービスかと思いますが、多くの分析サービスと統合されているサービスですので、これを機に Dive Deep してみてはいかがでしょうか。
この記事が、どなたかの役に立てば幸いです。