

概要
Glue は、分析や機械学習、アプリケーション開発のために、複数のデータソースからデータを簡単に抽出、移動、統合するためのサーバレスデータ統合サービスです。
公式 doc: https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html
2024 年 5 月現在で 70 を超える多様なデータソースと接続が可能となっています。AWS でデータ分析を行う場合、必ずと言っていいほど、何らかの形で関わるサービスかと思います。
Glue のアーキテクチャは以下の図のようになっており、関連するコンポーネントも多く、個人的にはとっつきにくいサービスだと感じました。
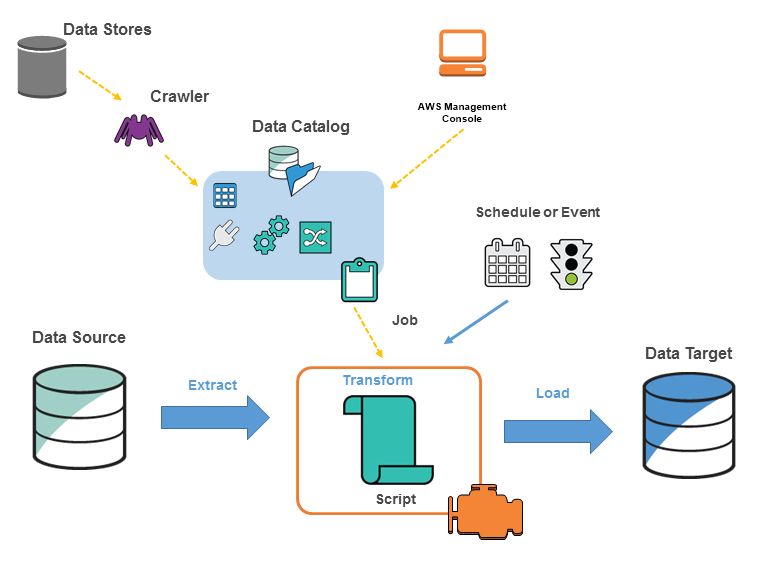
用語
コンポーネント
Glue を構成する各コンポーネントを紹介します。
データカタログ
データカタログは、Glue の永続的なメタデータストアです。Glue 環境を管理するためのテーブル定義、ジョブ定義、その他の制御情報を含みます。データカタログはテーブル定義などのメタデータのみを保存し、オリジナルデータを取り込むものではありません。オリジナルデータはデータソースにのみ存在します。
データレイクには形式が統一されていない様々なデータが書き込まれます。そのデータを利用するには、それぞれのデータの形式を把握する必要がありますが、事前に分析に必要な情報をデータカタログという形式でまとめておくことで、個別にデータの形式を調べる必要がなくなり、データカタログを使って同じデータを別のサービスからも分析しやすくなります。
次の図は、Glue クローラーがデータストアやその他の要素とやり取りをしてデータカタログを生成するフローを示しています。
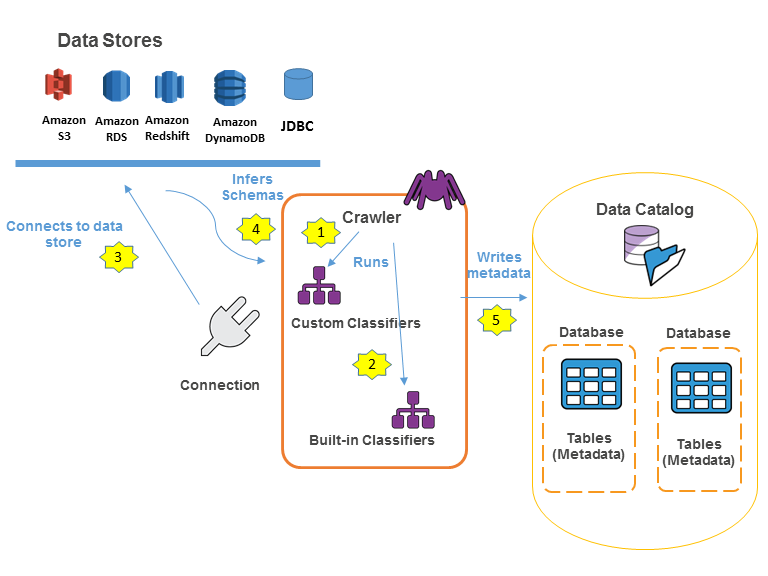
引用: https://docs.aws.amazon.com/glue/latest/dg/catalog-and-crawler.html
- クローラーは、カスタム分類子 (Classifiers) をもとにデータの形式とスキーマを推論します。
- データのスキーマに一致するカスタム分類子がない場合は、組み込み分類子を利用します。
- クローラーはデータストアに接続し、推論されたスキーマを作成します。
- クローラーはメタデータをデータカタログに書き込みます。
Glue データカタログを使用する他の AWS サービスとオープンソースプロジェクトとして
- Amazon Athena
- Amazon Redshift Spectrum
- Amazon EMR
- Apache Hive メタストア用 AWS Glue データカタログクライアント
があります。
データベース
データベースは、データカタログテーブルを保持するコンテナです。定義されたテーブルを整理するために利用され、テーブルは 1 つのデータベースに含まれます。
テーブルを格納するための入れ物として理解しておくといいかと思います。
テーブル
テーブルは、列の名前、データ型定義、パーティション情報、およびその他のプロパティで構成される、メタデータ定義です。データストア内のデータを扱うために必要な情報を格納します。
テーブルのプロパティには、テーブルの名前などの情報が含まれます。
https://docs.aws.amazon.com/glue/latest/dg/console-tables.html#console-tables-attributes
コンソールや API を利用してテーブルを手動で定義する場合、テーブルスキーマ (列名とデータ型) を設定します。クローラーがテーブルを定義する場合、組み込み分類子、もしくはカスタム分類子を利用して、これらの情報が決定されます。
テーブルパーティション
S3 に関するテーブルでは、パーティション分割されたテーブルを定義することができます。テーブル定義にテーブルのパーティションキーが含まれ、S3 内のデータを評価してテーブルをカタログ化する際に、個別のテーブルを追加するか、パーティション化されたテーブルを追加するか、いずれかを決定します。
パーティションテーブルを作成するには、次の条件を満たす必要があります。
- Glue が判断するファイルのスキーマが同様であること
- ファイルのデータ形式が同じであること
- ファイルの圧縮形式が同じであること