やること
Kendra インデックスを作成して S3 データソースのドキュメントを同期し、検索を行うまでの操作を確認します。
インデックスの作成
Kendra のコンソールを開き、”Create an Index” をクリックしてインデックスの作成をはじめます。

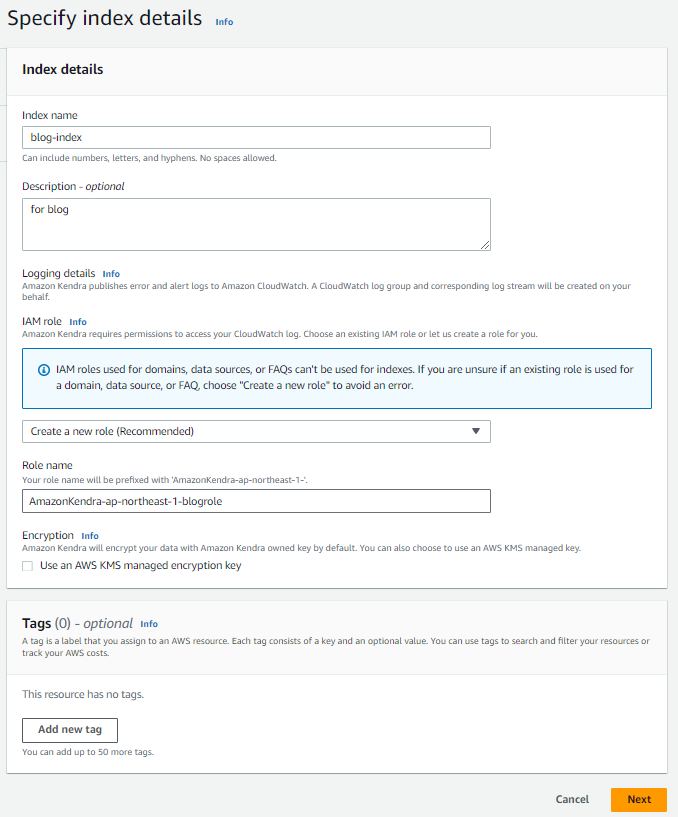
インデックス名と Kendra インデックスが利用する IAM role を設定します。
事前に IAM role を作成していない場合、インデックスの作成と同時に自動で必要な権限を持つ IAM role を作成できます。Kendra インデックスに必要なポリシーは、以下のドキュメントに記載されています。

- 「Index name」には、任意の Index 名を入力します。
- 「IAM role」には、インデックスが利用する IAM role を設定 (作成) します。
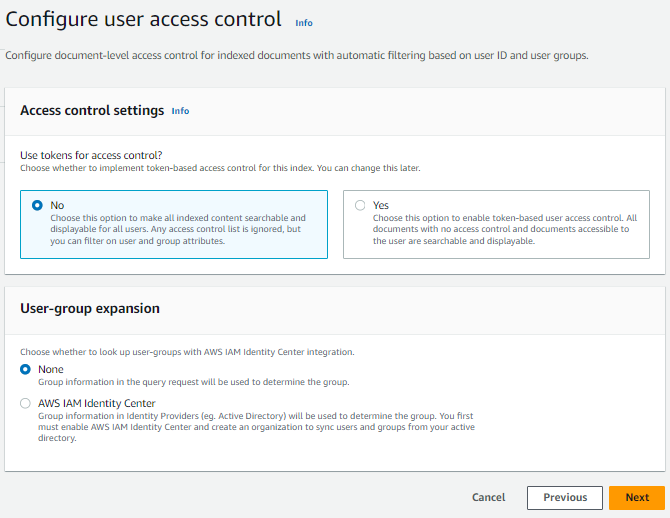
ユーザーのアクセス制御に関する設定です。今回は触らないため、デフォルトのままにします。
利用する Edition を選択します。今回は検証目的なので Developer edition を選択します。
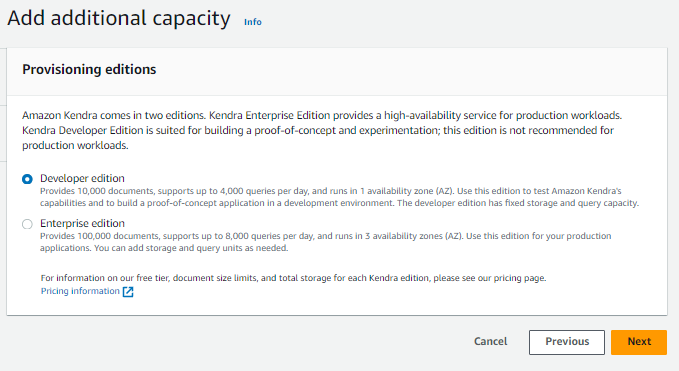
確認画面で設定内容を確認し、”Create” ボタンをクリックしてインデックスを作成します。
データソースの作成
インデックスの作成が完了したら、S3 データソースを作成してドキュメントを同期します。
左メニューから “Data sources” を選択し、”Amazon S3 connector” を追加します。
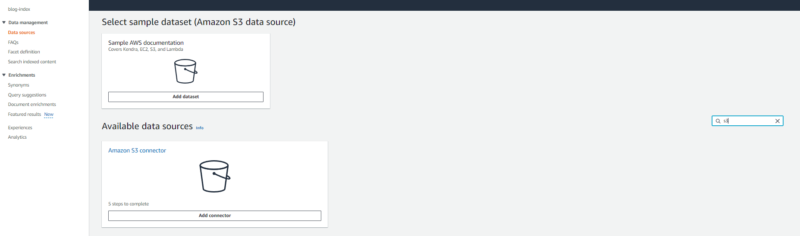
データソース名とデフォルトで使用する言語を設定します。
- 「Data source name」に任意のデータソース名を入力します。
- 「Default language」では、対象ドキュメントの言語を設定します。
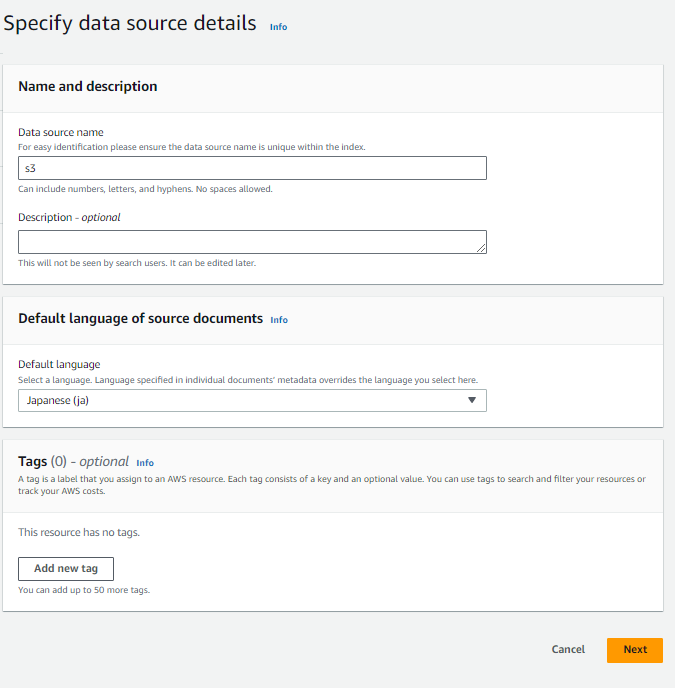
S3 データソースが利用する IAM role を設定します。先ほど設定したインデックスの IAM role と異なり、実際にデータを取得する際に必要になる権限を許可する必要があります。事前に作成した IAM role を指定することもできますし、コンソールで命名して自動で作成することもできます。
データソースの種類ごとに必要になるポリシーは以下のドキュメントに記載されています。

S3 データソースは VPC 構成をサポートしていますが、今回は使用しないのでデフォルトのままにします。
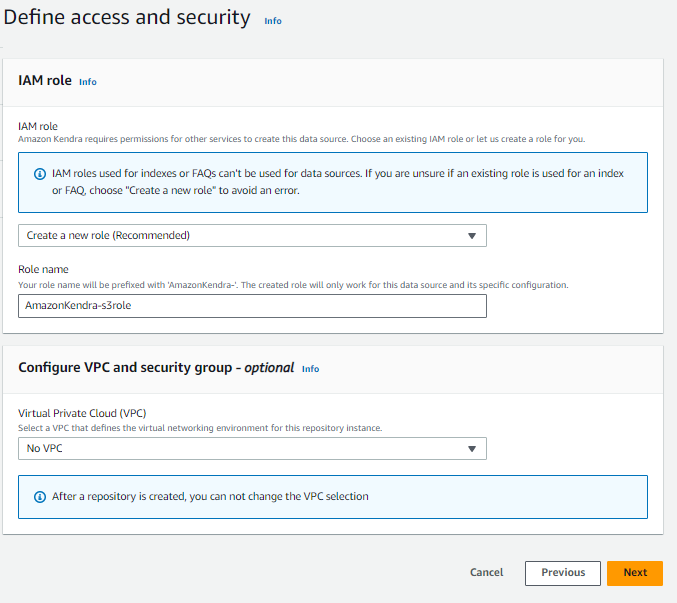
同期対象の設定では、ドキュメントを格納してある S3 バケットを指定します。今回は、そのほかの設定はデフォルトのままとします。
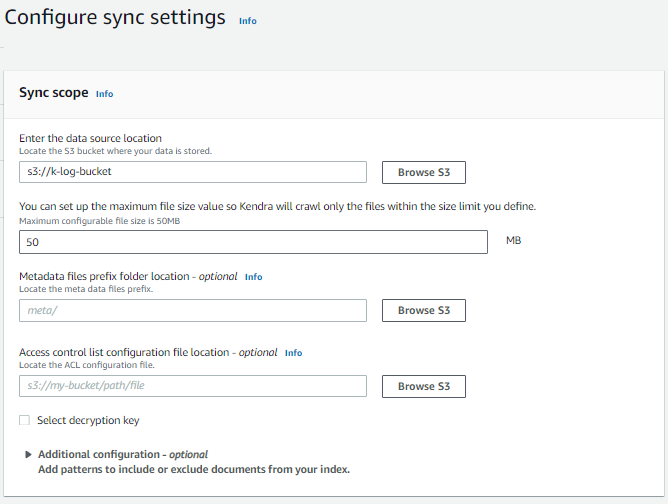
同期モードの設定では、フル同期を行うか、差分同期を行うか設定します。どちらを設定した場合も、初めての同期ではフル同期されます。
同期のスケジュールも設定可能です。基本的にはコンソールで用意された設定で十分かとは思いますが、より細かく制御したい場合には、cron 形式で指定することも可能です。今回は、手動で同期を実行するため、”Run on demand” を設定しています。

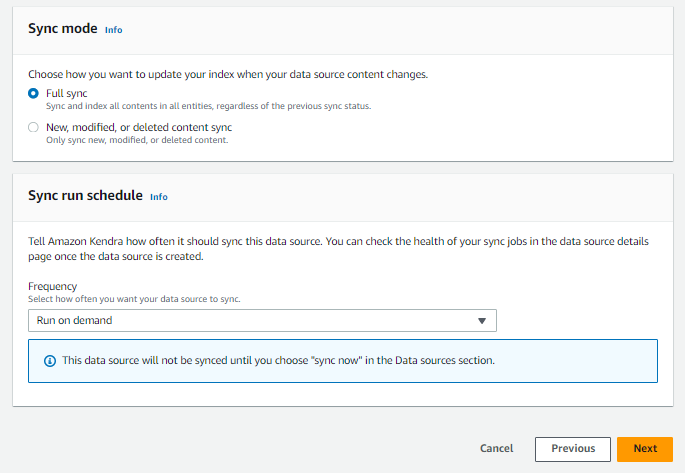
ドキュメントフィールドとインデックスフィールドのマッピングを設定できます。今回はデフォルトのままとします。
確認画面で設定内容を確認し、”Add data source” ボタンをクリックして S3 データソースを作成します。
作成が完了したら、作成したデータソースのコンソールを開いて “Sync now” ボタンをクリックして同期を開始します。同期対象のドキュメントの量に応じて、同期には数分から数時間かかる可能性があります。
検索テスト
インデックスへドキュメントの取り込みが完了したので、クエリを発行できるようになります。
Kendra では、コンソール上で簡単に検索動作を確認できるように検索コンソールが用意されています。左メニューの “Search indexed content” をクリックして検索コンソールを開きます。
検索コンソールを開いたら、右側のスパナアイコンから設定を開き、検索に使用する言語に日本語を設定します。今回、ドキュメントは日本語として解析してインデックに追加しているので、検索で使用する言語も日本語として解析される必要があります。
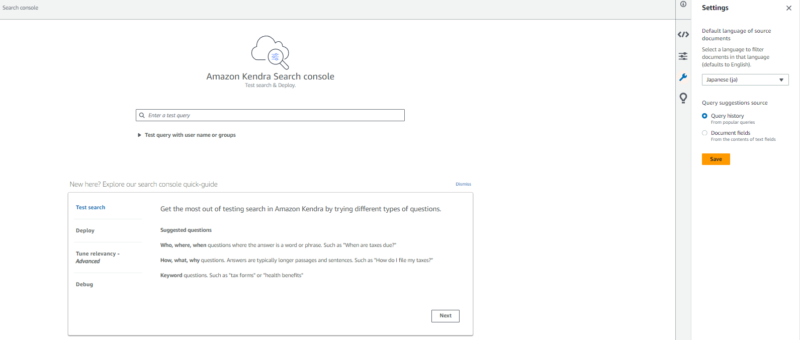
検索バーに質問を入力して検索を行います。
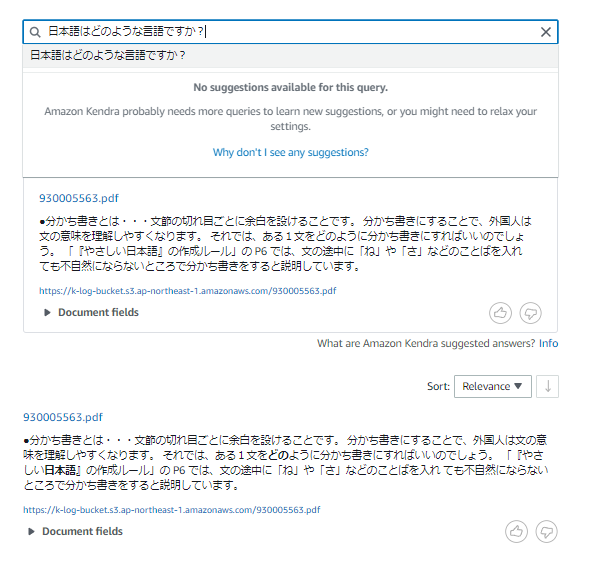
ここまでで Kendra インデックスにおける検索動作を確認できました。
検索コンソールを利用する以外にも、Query API を使用して検索結果を取得することもできます。

$ aws kendra query --index-id af34224d-f4d8-4706-8292-daa8c6d7da50 --query-text "やさしい" --attribute-filter '{"EqualsTo":{"Key":"_language_code","Value":{"StringValue": "ja"}}}' --query-result-type-filter DOCUMENT
{
"QueryId": "2f0cb871-69af-4012-a8dc-d6a0029fc32e",
"ResultItems": [
{
"Id": "2f0cb871-69af-4012-a8dc-d6a0029fc32e-5512a564-5d14-4ee5-b729-c12251926093",
"Type": "DOCUMENT",
"Format": "TEXT",
"AdditionalAttributes": [],
"DocumentId": "s3://k-log-bucket/930005563.pdf",
"DocumentTitle": {
"Text": "930005563.pdf",
"Highlights": []
},
"DocumentExcerpt": {
"Text": "1 章 はじめに \n \n\n\n2 章 「やさしい日本語」とは \n \n\n\n(1) 「やさしい日本語」とは? \n\n\n (2) なぜ、「やさしい日本語」が必要なの? \n\n\n (3) 誰を対象に使うの? \n\n\n (4) 実際にどういう場面で使われているの? \n\n\n \n\n\n3 章 「やさしい日本語」の作り方 \n \n\n\n(1) 「やさしい日本語」のための文書の選択 \n\n\n(2) 「やさしい日本語」のための文書の再構成 \n\n\n(3) 「やさしい日本語」変換のための基本ルール \n\n\n \n\n\n4 章 練習問題 \n\n\n「やさしい日本語」に書き換えよう!",
"Highlights": [
...検索コンソールはあくまで検索のテスト目的で利用するものとなります。
実際にユーザーが Kendra で検索を行うためには、ユーザーがアクセスする UI や Kendra へのクエリ実行処理などの開発が必要になります。
Kendra のデプロイ
Kendra のデプロイに関しては、ノーコードで AWS 上に検索画面を実装する Experience Builder を使った方法と React を使った実装方法が、AWS の公式手順として用意されています。

Experience Builder を使った方法
Experience Builder を使用して Kendra をデプロイする場合、アクセス管理は IAM Identity Center (IdC) を利用して制御されます。
IAM Identity Center でユーザーを作成
事前に IdC でユーザーを作成します。
IdC コンソールにて “有効にする” をクリックします。

左メニューの “ユーザー” を開き、”ユーザーを追加” をクリックしてユーザー登録を進めます。

今回は “test” というユーザーを作成しました。

ユーザー作成時に登録したメールアドレスに届く検証メールから、ユーザーの検証とパスワードの設定を行います。
AWS アクセスポータルにサインインすると、この時点では該当ユーザーへアプリケーションのアクセスは許可されていないため、何も表示されません。

ここまでで IdC の準備は完了です。
Experience Builder をデプロイ
続いて Experience Builder の設定を進めます。
Kendra コンソールの左メニューから “Experience” を開き、”Create experience” をクリックします。
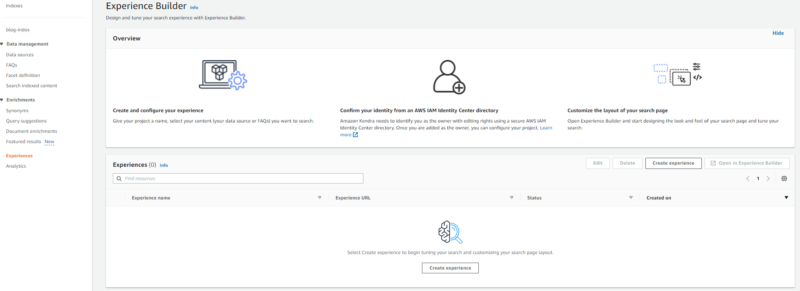
- 「Experience name」に任意の Experience 名を入力します。
- 「Content sources」では、Experience に含めるデータソースを選択します。
- 「IAM role」では、Experience が利用する IAM role を指定します。コンソールで自動作成することも可能です。
Experience で必要になるポリシーは以下のドキュメントに記載されています。

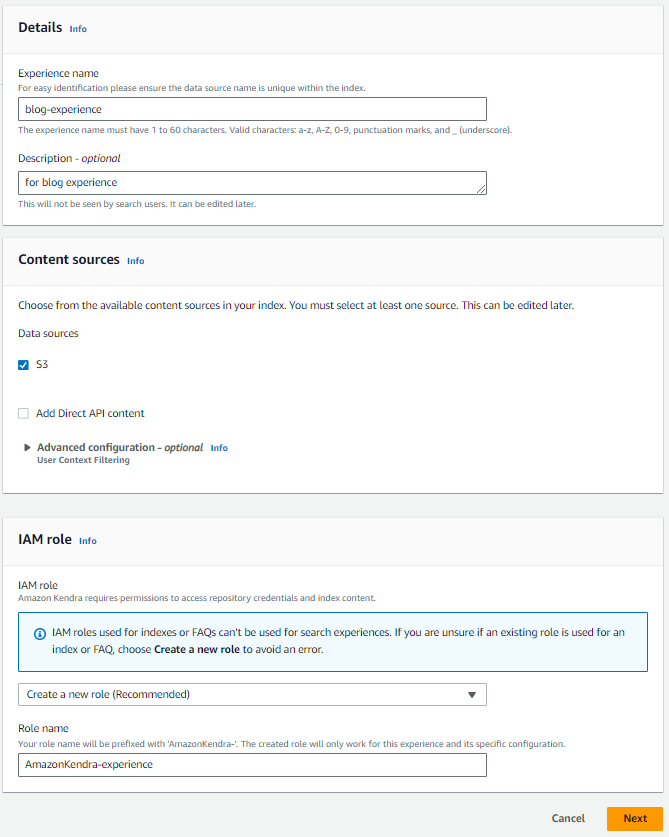
Experience へのアクセスを許可するユーザーを指定します。
確認画面で設定内容を確認し、”Create experience” ボタンをクリックして Experience を作成します。
Experience の作成が完了したら、作成された Experience の “Experience URL” を開きます。
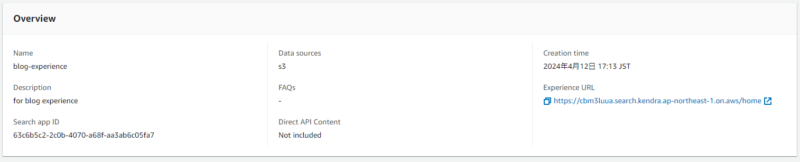
IdC に登録したユーザー情報でサインインし、デプロイされた検索画面にアクセスします。右上の “Switch to build mode” をクリックし、検索コンソールと同様に検索言語の設定を行ってから “Publish” をクリックして更新します。

検索バーに検索ワードを入力すると Kendra インデックスで検索することができます。
ユーザーからの利用
デプロイされた Experience に外部からアクセスするには、
- Experience URL へアクセスする
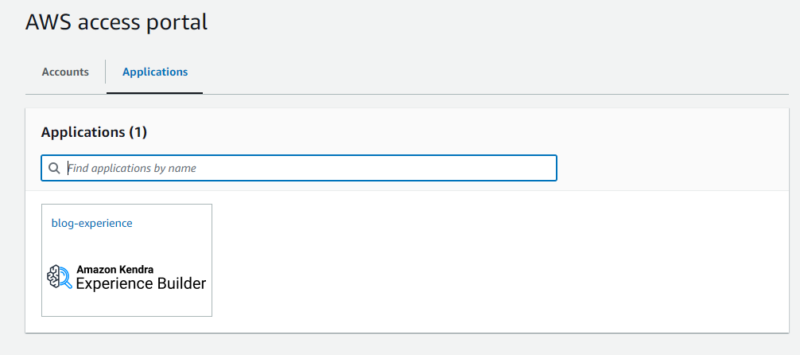
- AWS アクセスポータルからアクセスする
のいずれかの方法があります。
Experience URL は誰からでもアクセスできるため、検索を行うユーザーには、この URL を配布してアクセスしてもらう方法となります。
AWS アクセスポータルを利用する場合、AWS アクセスポータルへのサインイン後に利用可能な Experience を指定する方法となります。
React を使った方法
Experience Builder を利用した実装は、ノーコードで簡単ですが、検索画面のカスタマイズや IdC 以外でのアクセス制御を実現できません。
AWS では、より自由度の高い実装ができるように React のサンプルコードを公開しています。

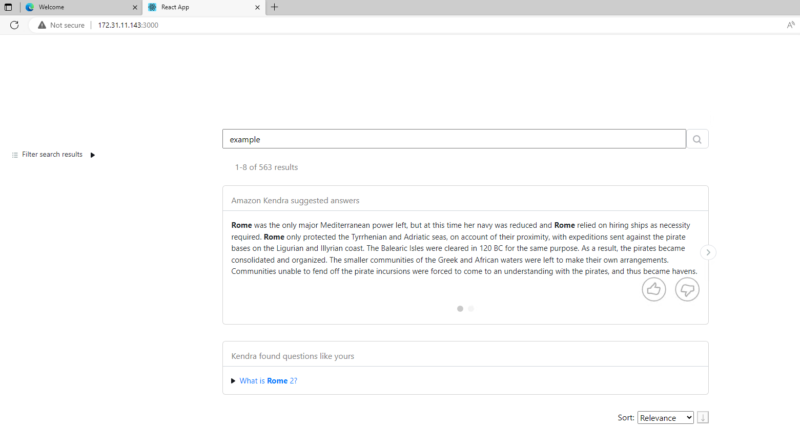
ドキュメントやサンプルコード内の README.md に記載の手順で設定を進めると以下のような検索画面が表示されます。